
Michael Chonoles, the author of “UML 2 for Dummies”, talks about “Modeling Myths” – damaging misconceptions people have that prevent them from adopting modeling in their projects.
Introduction to Modeling Myths
Modeling Myths are these damaging of misconceptions people have that prevent them from adopting modeling or UML on the projects.
Do I Really Need to Model Everything?
Do I model the extra information? The redundant information? It seems very expensive, very time consuming and needs too much resources. And the problem is, that they are really right. People who think that modeling everything is expensive are quite correct. But luckily, you don’t have to model all of it. You just you have to model “the biggest risks”.
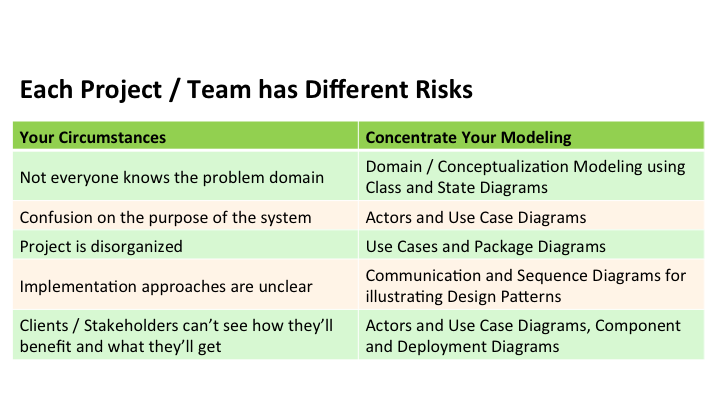
Every project, every team has different risks. You will hear some examples you might find similar on your project.
-Domain
For example, you might find that not everyone understands the domain or the problem space. So, what you might use is conceptualization and domain-style modeling of your Class Diagrams or State Diagrams, so that it shows what the real world is like.
-Purpose
You might have problems where people on your project don’t know what the purpose of the project is. What are the things, what are the problems that you are solving. Well, use UseCases and Actors to show what you are trying to accomplish.
-Organization
Sometimes you have a problem with the organization. People don’t quite understand what tasks they are assigned, and who’s doing what. Use Package diagrams, or sometimes Use Case diagrams to help you split them up into individual tasks and problems to work on.
-Implementation Approach
Sometimes you find that there are implementation issues. People don’t really get a feel for how this thing might be implemented. Use Sequence diagrams or Collaboration diagrams to help you understand how that might work together.

Donts
Don’t model things like Legacy Code if it’s well understood. Don’t model statemachines of simple on/off switches because they’’re trivial, they’’re on or off –and it’s a waste of time.
Don’t model parts of the system that are already known or similar to the other parts. If you model it the first time, and the second time around, you are modeling a different part of the system that works like the first, just reference the first one.
Don’t model anything that doesn’t really address a risk. Spend your time modeling where there’’s a big return on investment.
Let’s give an example that might help you understand.

Confusing Model
You can see here some modeling that is a little confusing. If everyone in the project is working on different parts, you are going to come up with something pretty confusing and hard to understand, and hard to see if there is any problems. So, what we are going to have to do is take some of this stuff out.
There’s some stuff that’s “already known“. We’ll, take that out. We don’’t need to model that.
But there’’s more. It’’s still confusing. Let’s take out stuff, and not model anything doesn’t address a need. Let’s get rid of that.
It’’s still confusing, still hard to see. What else could we avoid spending or wasting money, and time, and resources on? We could have not modeled the “Unwanted Information“.
So now, things are improving. What else could we take out? Things that are trivial like the statemachines, the easy stuff. Let’s get rid of the easy stuff. And we are getting better.
And get rid of “Useless Detail” . So what’s left is the biggest risk.
But now we can see there’s some problems. Things aren’t straight. That’s one of our problems. We didn’t do it really right, so we can straighten this.
And then we see one more problem left. The serious one. We spelled “risk” incorrectly. So now we fixed that. If we would have started with just the area of biggest risk, we would have addressed our problems and not spent our resources on things we didn’t need.
Thank you Michael for this great topic!
-Kenji

Its a great UML tutorial , easier to understand when a video is included. Pictures / graphs and done a good job too. When it comes to uml diagrams better to see good diagrams examples since there are more than 11 types.